Nov 12, 2024: We have released Spider 2.0 full paper, data and code. Follow the guideline to submit your scores to the leaderboard!
Aug 28, 2024: The early access version of Spider 2.0 (a more realistic and challenging text-to-SQL task) is now available! We expect to release the whole dataset in 1-2 weeks. As this is a preliminary release, there may be errors. Your feedback would be invaluable in refining the dataset!
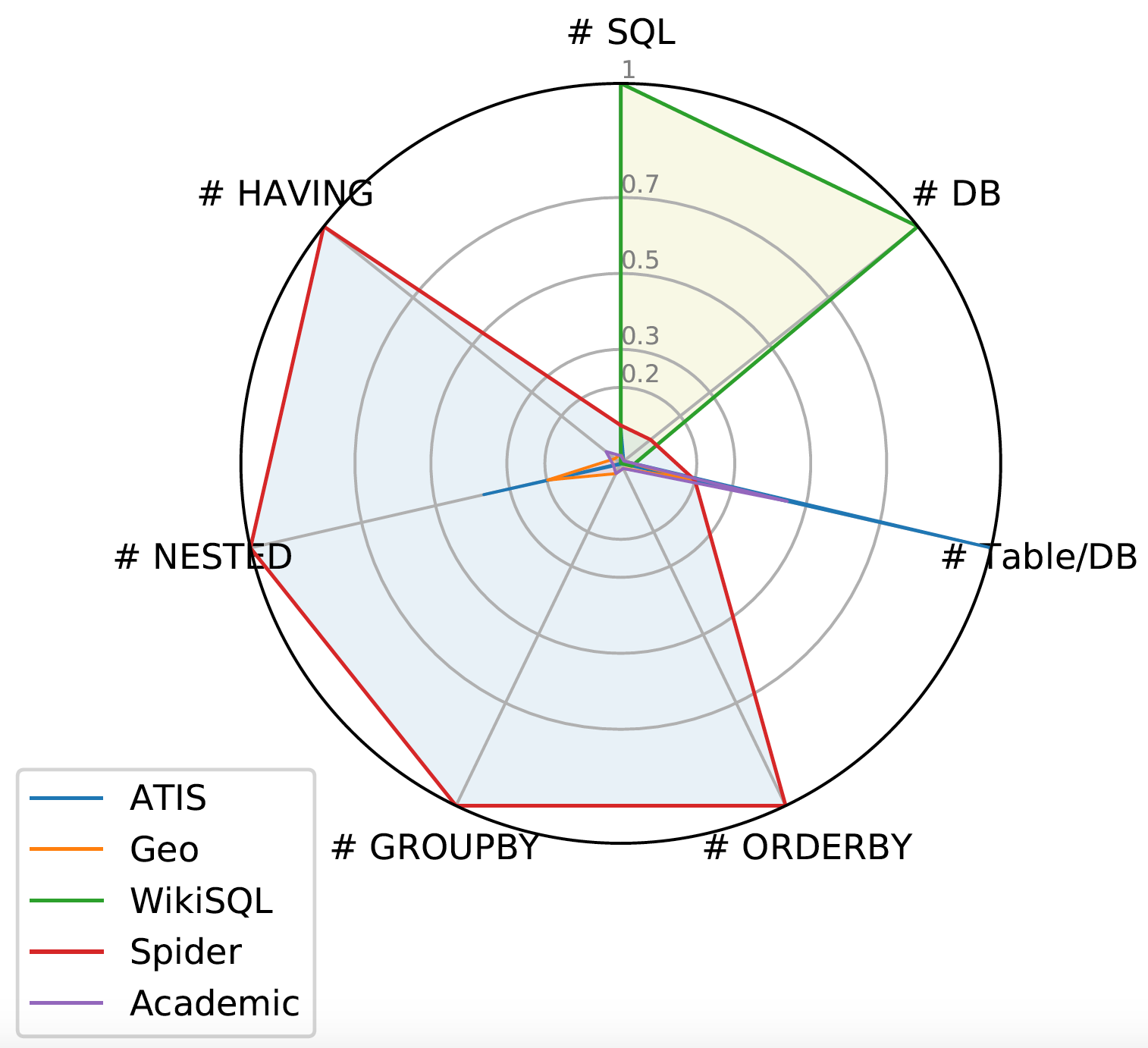
Spider is a large-scale complex and cross-domain semantic parsing and text-to-SQL dataset annotated by 11 Yale students. The goal of the Spider challenge is to develop natural language interfaces to cross-domain databases. It consists of 10,181 questions and 5,693 unique complex SQL queries on 200 databases with multiple tables covering 138 different domains. In Spider 1.0, different complex SQL queries and databases appear in train and test sets. To do well on it, systems must generalize well to not only new SQL queries but also new database schemas.


| Rank | Model | Test |
|---|---|---|
|
1 Nov 2, 2023 |
MiniSeek
Anonymous Code and paper coming soon |
91.2 |
|
1 Aug 20, 2023 |
DAIL-SQL + GPT-4 + Self-Consistency
Alibaba Group (Gao and Wang et al.,'2023) code |
86.6 |
|
2 Aug 9, 2023 |
DAIL-SQL + GPT-4
Alibaba Group (Gao and Wang et al.,'2023) code |
86.2 |
|
3 October 17, 2023 |
DPG-SQL + GPT-4 + Self-Correction
Anonymous Code and paper coming soon |
85.6 |
|
4 Apr 21, 2023 |
DIN-SQL + GPT-4
University of Alberta (Pourreza et al.,'2023) code |
85.3 |
|
5 July 5, 2023 |
Hindsight Chain of Thought with GPT-4
Anonymous Code and paper coming soon |
83.9 |
|
6 Jun 1, 2023 |
C3 + ChatGPT + Zero-Shot
Zhejiang University & Hundsun (Dong et al.,'2023) code |
82.3 |
|
7 July 5, 2023 |
Hindsight Chain of Thought with GPT-4 and Instructions
Anonymous Code and paper coming soon |
80.8 |
|
8 Feb 7, 2023 |
RESDSQL-3B + NatSQL (DB content used)
Renmin University of China (Li et al., AAAI'23) code |
79.9 |
|
9 Nov 21, 2022 |
SeaD + PQL (DB content used)
Anonymous |
78.5 |
|
10 Apr 21, 2023 |
DIN-SQL + CodeX
University of Alberta (Pourreza et al.,'2023) code |
78.2 |
|
11 August 10, 2023 |
T5-3B+NatSQL+Token Preprocessing (DB content used)
George Mason University & MIT (Rai et al., ACL '23) code |
78.0 |
|
12 Sep 14, 2022 |
CatSQL + GraPPa (DB content used)
Anonymous |
78.0 |
|
13 Sep 13, 2022 |
Graphix-3B+PICARD (DB content used)
Alibaba DAMO & HKU STAR & SIAT (Li et al., AAAI'2023) code |
77.6 |
|
14 Sep 1, 2022 |
SHiP+PICARD (DB content used)
AWS AI Labs (Zhao et al.,'22) |
76.6 |
|
15 Apr 4, 2023 |
RASAT + NatSQL + Reranker (DB content used)
Anonymous Paper coming soon |
76.5 |
|
16 Dec 15, 2022 |
N-best List Rerankers + PICARD (DB content used)
Alexa AI (Zeng et al., IEEE SLT 2023) |
75.9 |
|
17 Jun 4, 2022 |
RASAT+PICARD (DB content used)
SJTU LUMIA & Netmind.AI (Qi et al., EMNLP'22) code |
75.5 |
|
18 May 8, 2022 |
T5-SR (DB content used)
Anonymous |
75.2 |
|
19 Aug 12, 2022 |
RESDSQL+T5-1.1-lm100k-xl (DB content used)
Anonymous |
75.1 |
|
20 Jul 14, 2021 |
T5-3B+PICARD (DB content used)
Element AI, a ServiceNow company (Scholak et al., EMNLP'21) code |
75.1 |
|
21 Aug 12, 2022 |
RESDSQL+T5-1.1-lm100k-large (DB content used)
Anonymous |
74.8 |
|
22 May 18, 2022 |
SeaD + SP (DB content used)
Anonymous |
74.1 |
|
23 May 4, 2021 |
RATSQL+GAP+NatSQL (DB content used)
Queen Mary University of London (Gan et al., EMNLP Findings'21) code |
73.3 |
|
24 August 10, 2021 |
T5-Base+NatSQL+Token Preprocessing (DB content used)
George Mason University & MIT (Rai et al., ACL '23) code |
71.1 |
|
25 Mar 10, 2021 |
SmBoP + GraPPa (DB content used)
Tel-Aviv University & Allen Institute for AI (Rubin and Berant, NAACL'21) code |
71.1 |
|
26 Aug 05, 2021 |
RaSaP + ELECTRA (DB content used)
Ant Group, ZhiXiaoBao & Ada (Huang et al.,'21) |
70.0 |
|
27 Nov 24, 2020 |
BRIDGE v2 + BERT(ensemble) (DB content used)
Salesforce Research (Lin et al., EMNLP-Findings '20) code |
68.3 |
|
28 Jan 16, 2021 |
COMBINE (DB content used)
Novelis.io Research (Youssef et al.,'21) |
68.2 |
|
29 Jul 22, 2022 |
T5QL-Base (DB content used)
Anonymous |
66.8 |
|
30 Nov 24, 2020 |
BRIDGE v2 + BERT (DB content used)
Salesforce Research (Lin et al., EMNLP-Findings '20) code |
64.3 |
|
31 May 30, 2020 |
AuxNet + BART (DB content used)
Anonymous |
62.6 |
|
32 May 30, 2020 |
BRIDGE + BERT (DB content used)
Salesforce Research (Lin et al., EMNLP-Findings '20) code |
59.9 |
|
33 May 20, 2020 |
GAZP + BERT (DB content used)
University of Washington & Facebook AI Research (Zhong et al., EMNLP '20) |
53.5 |
| Rank | Model | Dev | Test |
|---|---|---|---|
|
1 Nov 2, 2023 |
MiniSeek
Anonymous Code and paper coming soon |
80.3 | 81.5 |
|
1 Sep 13, 2022 |
Graphix-3B + PICARD (DB content used)
Alibaba DAMO & HKU STAR & SIAT (Li et al., AAAI'2023) code |
77.1 | 74.0 |
|
2 Sep 14, 2022 |
CatSQL + GraPPa (DB content used)
Anonymous |
78.6 | 73.9 |
|
3 Sep 1, 2022 |
SHiP + PICARD (DB content used)
AWS AI Labs (Zhao et al.,'22) |
77.2 | 73.1 |
|
4 May 23, 2022 |
G³R + LGESQL + ELECTRA (DB content used)
Southeast University & Tencent Cloud Xiaowei (Xiang et al., ACL-Findings '23) |
78.1 | 72.9 |
|
6 Aug 12, 2022 |
RESDSQL+T5-1.1-lm100k-xl (DB content used)
Anonymous |
78.1 | 72.4 |
|
6 May 8, 2022 |
T5-SR (DB content used)
Anonymous |
77.2 | 72.4 |
|
7 Dec 15, 2022 |
N-best List Rerankers + PICARD (DB content used)
Alexa AI (Zeng et al., IEEE SLT 2023) |
76.4 | 72.2 |
|
8 Sep 1, 2021 |
S²SQL + ELECTRA (DB content used)
Alibaba DAMO (Hui et al., ACL-Findings '22) code |
76.4 | 72.1 |
|
9 Feb 7, 2023 |
RESDSQL-3B + NatSQL (DB content used)
Renmin University of China (Li et al., AAAI'23) code |
80.5 | 72.0 |
|
10 Jun 1, 2021 |
LGESQL + ELECTRA (DB content used)
SJTU X-LANCE Lab & AISpeech (Cao et al., ACL'21) code |
75.1 | 72.0 |
|
11 Jul 14, 2021 |
T5-3B+PICARD (DB content used)
Element AI, a ServiceNow company (Scholak et al., EMNLP'21) code |
75.5 | 71.9 |
|
12 Aug 12, 2022 |
RESDSQL+T5-1.1-lm100k-large (DB content used)
Anonymous |
76.6 | 71.1 |
|
13 Jun 4, 2022 |
RASAT+PICARD (DB content used)
SJTU LUMIA & Netmind.AI (Qi et al., EMNLP'22) code |
75.3 | 70.9 |
|
14 Nov 19, 2020 |
DT-Fixup SQL-SP + RoBERTa (DB content used)
Borealis AI (Xu et al., ACL'21) code |
75.0 | 70.9 |
|
15 Nov 19, 2020 |
RAT-SQL + GraPPa + Adv (DB content used)
Anonymous |
75.5 | 70.5 |
|
16 Oct 18, 2021 |
RATSQL++ + ELECTRA (DB content used)
Anonymous |
75.7 | 70.3 |
|
17 Nov 19, 2020 |
SADGA + GAP (DB content used)
DMIR Lab (Cai and Yuan et al., NeurIPS'21) code |
73.1 | 70.1 |
|
18 Dec 25, 2020 |
RATSQL + GraPPa + GP (DB content used)
OCFT Gamma Big Data Lab (Zhao et al.,'21) |
72.8 | 69.8 |
|
19 Sep 08, 2020 |
RATSQL + GAP (DB content used)
University of Waterloo & AWS AI Labs (Shi et al., AAAI'21) code |
71.8 | 69.7 |
|
20 Apr 4, 2023 |
RASAT + NatSQL + Reranker (DB content used)
Anonymous Paper coming soon |
73.6 | 69.6 |
|
20 Aug 18, 2020 |
RATSQL + GraPPa (DB content used)
Yale & Salesforce Research (Yu et al., ICLR'21) code |
73.4 | 69.6 |
|
22 Mar 10, 2021 |
SmBoP + GraPPa (DB content used)
Tel-Aviv University & Allen Institute for AI (Rubin and Berant, NAACL'21) code |
74.7 | 69.5 |
|
23 Aug 05, 2021 |
RaSaP + ELECTRA (DB content used)
Ant Group, ZhiXiaoBao & Ada (Huang et al.,'21) |
74.7 | 69.0 |
|
24 May 4, 2021 |
RATSQL+GAP+NatSQL (DB content used)
Queen Mary University of London (Gan et al., EMNLP Findings'21) code |
- | 68.7 |
|
25 Nov 20, 2020 |
RAT-SQL + STRUG (DB content used)
Microsoft Research & OSU (Deng et al., NAACL '21) |
72.6 | 68.4 |
|
26 Jun 1, 2021 |
LGESQL + BERT (DB content used)
SJTU X-LANCE Lab & AISpeech (Cao et al., ACL'21) code |
74.1 | 68.3 |
|
27 Jan 16, 2021 |
COMBINE (DB content used)
Novelis.io Research (Youssef et al.,'21) |
71.4 | 67.7 |
|
28 Nov 24, 2020 |
BRIDGE v2 + BERT(ensemble) (DB content used)
Salesforce Research (Lin et al., EMNLP-Findings '20) code |
71.1 | 67.5 |
|
29 Sep. 8, 2020 |
ShadowGNN + RoBERTa (DB content used)
SJTU X-LANCE Lab & AISpeech (Chen et al., NAACL'21) |
72.3 | 66.1 |
|
30 Jul. 22, 2022 |
T5QL-Base (DB content used)
Anonymous |
69.3 | 65.9 |
|
31 May 02, 2020 |
RATSQL v3 + BERT (DB content used)
Microsoft Research (Wang and Shin et al., ACL '20) code |
69.7 | 65.6 |
|
32 Dec. 07, 2020 |
DuoRAT + BERT (DB content used)
Anonymous |
- | 65.4 |
|
33 Sep. 8, 2020 |
YCSQL + BERT (DB content used)
Anonymous |
- | 65.3 |
|
34 Jan. 29, 2021 |
ETA + BERT (DB content used)
Microsoft Research Asia (Liu et al., ACL-Findings '21) |
70.8 | 65.3 |
|
35 Nov 24, 2020 |
BRIDGE v2 + BERT (DB content used)
Salesforce Research (Lin et al., EMNLP-Findings '20) code |
70.0 | 65.0 |
|
36 October 17, 2023 |
DPG-SQL + GPT-4 + Self-Correction
Anonymous Code and paper coming soon |
- | 64.7 |
|
37 Sep. 8, 2020 |
GP-RATSQL + BERT (DB content used)
Anonymous |
- | 64.5 |
|
38 Nov. 25, 2020 |
RATSQL-HPFT + BERT (DB content used)
Anonymous |
- | 64.4 |
|
39 Feb 2, 2021 |
LGESQL + GLOVE (DB content used)
SJTU X-LANCE Lab & AISpeech (Cao et al., ACL'21) code |
67.6 | 62.8 |
|
40 May 31, 2020 |
AuxNet + BART (DB content used)
Anonymous |
70.0 | 61.9 |
|
41 Dec 13, 2019 |
RATSQL v2 + BERT (DB content used)
Microsoft Research (Wang and Shin et al., ACL '20) code |
65.8 | 61.9 |
|
42 May 31, 2020 |
AuxNet + BART
Anonymous |
68.0 | 61.3 |
|
43 Feb 18, 2020 |
RYANSQL v2 + BERT
Kakao Enterprise (Choi et al., '20) |
70.6 | 60.6 |
|
44 Oct 19, 2020 |
SmBoP + BART
Tel-Aviv University & Allen Institute for AI (Rubin and Berant '20) |
66.0 | 60.5 |
|
45 Dec 18, 2019 |
IRNet++ + XLNet (DB content used)
Anonymous |
65.5 | 60.1 |
|
46 Apr 21, 2023 |
DIN-SQL + GPT-4
University of Alberta (Pourreza et al.,'2023) code |
60.1 | 60 |
|
47 May 30, 2020 |
BRIDGE + BERT (DB content used)
Salesforce Research (Lin et al., EMNLP-Findings '20) code |
65.5 | 59.2 |
|
48 Nov 12, 2019 |
RYANSQL + BERT
Kakao Enterprise (Choi et al., '20) |
66.6 | 58.2 |
|
49 Dec 13, 2019 |
RATSQL v2 (DB content used)
Microsoft Research (Wang and Shin et al., ACL '20) code |
62.7 | 57.2 |
|
50 Apr 21, 2023 |
DIN-SQL + CodeX
University of Alberta (Pourreza et al.,'2023) code |
57.2 | 57 |
|
51 Dec 13, 2019 |
SLSQL + BERT + Data Annotation
National University of Singapore (Lei and Wang et al., EMNLP '20) code |
60.8 | 55.7 |
|
52 Dec 13, 2019 |
EditSQL+LSL + BERT
Anonymous |
57.9 | 55.2 |
|
53 June 24, 2019 |
IRNet v2 + BERT
Microsoft Research Asia |
63.9 | 55.0 |
|
54 Sep 20, 2019 |
GIRN + BERT
Anonymous |
60.2 | 54.8 |
|
55 May 19, 2019 |
IRNet + BERT
Microsoft Research Asia (Guo and Zhan et al., ACL '19) code |
61.9 | 54.7 |
|
56 Nov 4, 2019 |
GNN + Bertrand-DR
Got It R&D (Kelkar et al., '20) code |
57.9 | 54.6 |
|
57 Apr 8, 2020 |
CNSQL
Anonymous |
58.0 | 54.0 |
|
58 Sep 19, 2019 |
RATSQL
Anonymous |
60.6 | 53.7 |
|
59 Sep 1, 2019 |
EditSQL + BERT
Yale University & Salesforce Research (Zhang et al., EMNLP '19) code |
57.6 | 53.4 |
|
60 May 21, 2020 |
GAZP + BERT
University of Washington & Facebook AI Research (Zhong et al., EMNLP '20) |
- | 53.3 |
|
61 May 21, 2020 |
NatSQL v3
Anonymous |
- | 53.2 |
|
62 May 28, 2020 |
IRNET+ GNN
Anonymous |
- | 49.6 |
|
63 June 24, 2019 |
IRNet v2
Microsoft Research Asia |
55.4 | 48.5 |
|
64 Aug 30, 2019 |
Global-GNN (DB content used)
Tel-Aviv University & Allen Institute for AI (Bogin et al., EMNLP '19) code |
52.7 | 47.4 |
|
65 Dec 13, 2019 |
LSL
Anonymous |
56.8 | 47.0 |
|
66 Apr 5, 2020 |
GraphSQL
Anonymous |
52.8 | 46.9 |
|
67 May 19, 2019 |
IRNet
Microsoft Research Asia (Guo and Zhan et al., ACL '19) code |
53.2 | 46.7 |
|
68 Mar 17, 2020 |
SG-IRNet
Anonymous |
- | 46.6 |
|
69 Dec 13, 2019 |
NatSQL v2
Anonymous |
52.0 | 46.4 |
|
70 June 11, 2019 |
HSRNet
Anonymous |
51.5 | 45.6 |
|
71 June 12, 2019 |
CFGN
Anonymous |
48.7 | 44.1 |
|
72 Aug 31, 2019 |
NatSQL
Anonymous |
52.9 | 42.5 |
|
73 May 16, 2019 |
GNN
Tel-Aviv University & Allen Institute for AI (Bogin et al., ACL '19) code |
40.7 | 39.4 |
|
74 Feb 25, 2019 |
SASeq
Anonymous |
40.8 | 37.4 |
|
75 May 30, 2019 |
GrammarSQL
Allen Institute for AI (Lin et al., '19) |
34.8 | 33.8 |
|
76 Sep 1, 2019 |
EditSQL
Yale University & Salesforce Research (Zhang et al., EMNLP '19) code |
36.4 | 32.9 |
|
77 Dec 13, 2019 |
GuideSQL
Anonymous |
36.8 | 31.5 |
|
78 Sep 20, 2018 |
SyntaxSQLNet + augment
Yale University (Yu et al., EMNLP '18) code |
24.8 | 27.2 |
|
79 April 18, 2019 |
RCSQL
SAP Labs Korea (Lee, EMNLP'19) |
28.5 | 24.3 |
|
80 Sep 20, 2018 |
SyntaxSQLNet
Yale University (Yu et al., EMNLP '18) code |
18.9 | 19.7 |
|
81 Sep 20, 2018 |
SQLNet
Shanghai Jiao Tong University (modified by Yale) (Xu et al., '18) code |
10.9 | 12.4 |
|
82 Sep 20, 2018 |
TypeSQL
Yale University (Yu et al., NAACL '18) code |
8.0 | 8.2 |
|
83 Sep 20, 2018 |
Seq2Seq + attention
University of Edinburgh (modified by Yale) (Dong and Lapata, ACL '16) code |
1.8 | 4.8 |