Nov 12, 2024: We have released Spider 2.0 full paper, data and code. Follow the guideline to submit your scores to the leaderboard!
Aug 28, 2024: The early access version of Spider 2.0 (a more realistic and challenging text-to-SQL task) is now available! We expect to release the whole dataset in 1-2 weeks. As this is a preliminary release, there may be errors. Your feedback would be invaluable in refining the dataset!
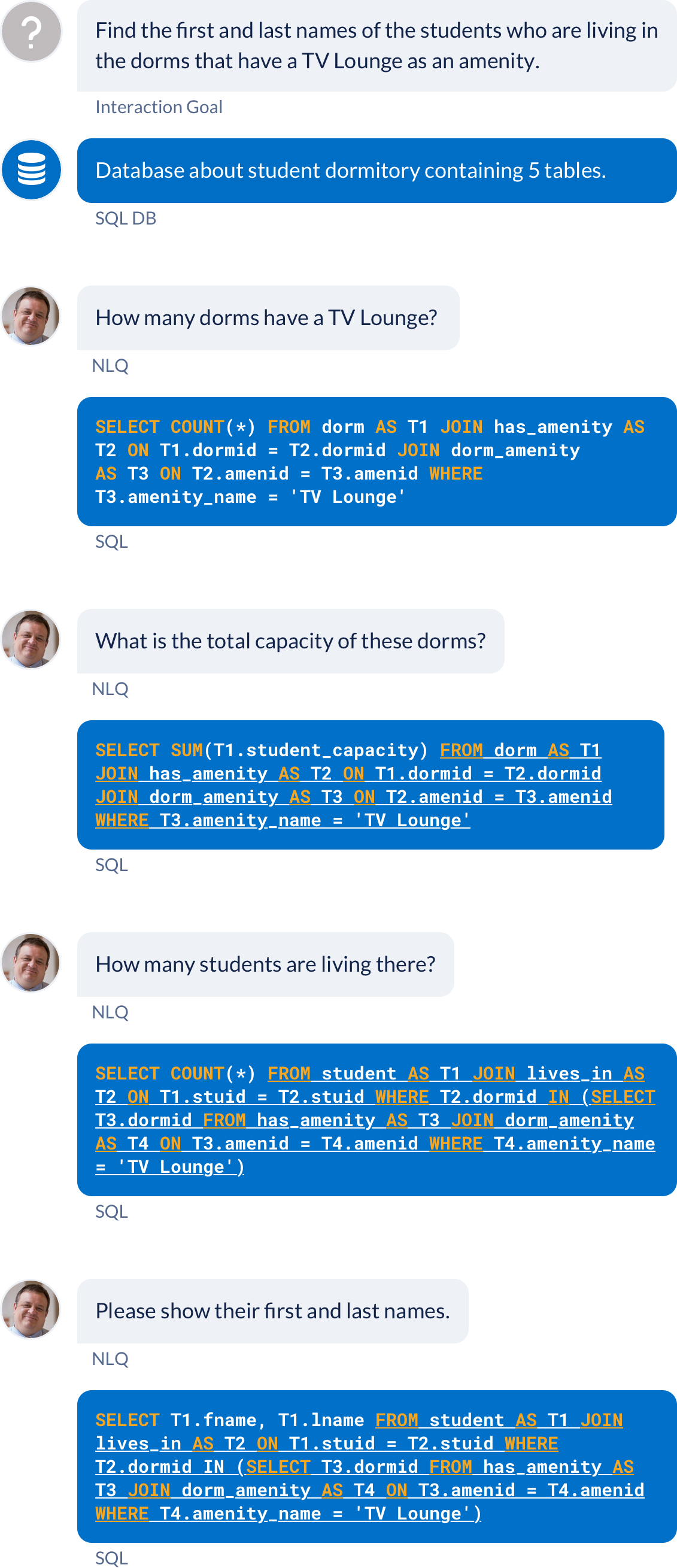 Another example:
Another example:


| Rank | Model | Question Match | Interaction Match |
|---|---|---|---|
|
1 Jun 4, 2022 |
RASAT + PICARD
SJTU LUMIA & Netmind.AI (Qi et al., EMNLP'22) code |
74.0 | 52.6 |
|
2 May 24, 2020 |
TreeSQL V2 + BERT
Anonymous |
48.5 | 21.6 |
|
3 May 21, 2020 |
GAZP + BERT
University of Washington & Facebook AI Research (Zhong et al., EMNLP '20) |
44.6 | 19.7 |
| Rank | Model | Question Match | Interaction Match |
|---|---|---|---|
|
1 Feb 14, 2022 |
STAR
Alibaba DAMO & SIAT (Cai and Li et al., EMNLP-Findings '22) code demo |
67.4 | 46.6 |
|
2 Jun 4, 2022 |
RASAT + PICARD
SJTU LUMIA & Netmind.AI (Qi et al., EMNLP'22) code |
67.7 | 45.2 |
|
3 Apr 27, 2022 |
CQR-SQL
Tencent Cloud Xiaowei (Xiao et al.,'22) |
68.2 | 44.4 |
|
4 Oct 8, 2021 |
RAT-SQL-TC + GAP
Meituan & PKU (Li et al.,'21) |
65.7 | 43.2 |
|
5 Oct 18, 2021 |
HIE-SQL + GraPPa
Alibaba DAMO (Zheng et al. ACL-Findings '22) |
64.6 | 42.9 |
|
6 Sep. 21, 2020 |
RAT-SQL + SCoRe
Yale & Microsoft Research & PSU (Yu et al. ICLR '21) |
62.4 | 38.1 |
|
7 Oct 21, 2020 |
WaveSQL+BERT
Anonymous |
58.7 | 33.3 |
|
8 July 08, 2020 |
R²SQL + BERT
Alibaba DAMO (Hui et al. AAAI '21) code |
55.8 | 30.8 |
|
9 May 26, 2020 |
IGSQL + BERT
Peking University (Cai et al. EMNLP '20) code |
51.2 | 29.5 |
|
10 Jun. 02, 2020 |
MIE + BERT
Anonymous |
49.6 | 27.1 |
|
11 May 04, 2020 |
SubTreeSQL + BERT
Anonymous |
47.4 | 25.5 |
|
12 Sep 1, 2019 |
EditSQL + BERT
Yale University & Salesforce Research (Zhang et al. EMNLP '19) code |
47.9 | 25.3 |
|
13 May 03, 2020 |
TreeSQL V2 + BERT
Anonymous |
48.1 | 25.0 |
|
14 May 22, 2020 |
MH-LTA + BERT
Anonymous |
48.5 | 24.7 |
|
15 Jan 15, 2020 |
TreeSQL + BERT
Anonymous |
46.3 | 24.3 |
|
16 May 21, 2020 |
GAZP + BERT
University of Washington & Facebook AI Research (Zhong et al., EMNLP '20) |
45.9 | 23.5 |
|
17 Feb 13, 2020 |
ConcatSQL + BERT
Anonymous |
46.3 | 22.4 |
|
18 Apr 21, 2021 |
MemCE
UoE (Jain et al., TACL '21) |
40.3 | 16.7 |
|
19 Feb 13, 2020 |
ConcatSQL
Anonymous |
39.0 | 16.3 |
|
20 Dec 13, 2019 |
GuideSQL
Anonymous |
34.4 | 13.1 |
|
21 May 17, 2019 |
CD-Seq2Seq
Yale University & Salesforce Research (Yu et al. ACL '19) code |
23.2 | 7.5 |
|
22 May 17, 2019 |
SyntaxSQL-con
Yale University (Yu et al. EMNLP '18) code |
20.2 | 5.2 |